
どーも、ぐるたか@guru_takaです。
今回は条件付きGAN(以下、CGAN)をPyTorchで実装する方法を紹介していきます。
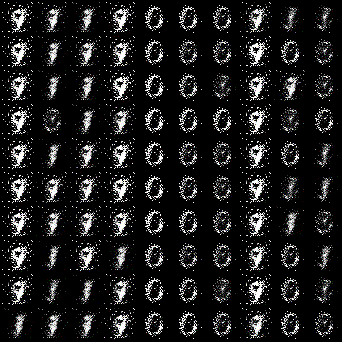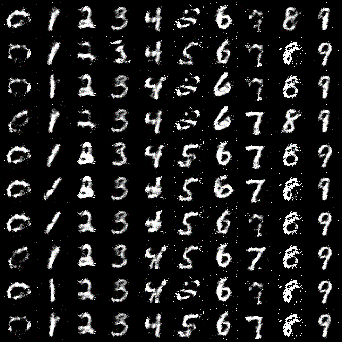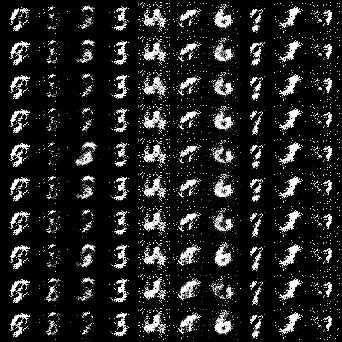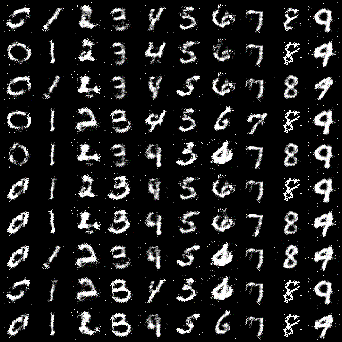
以前、紹介した元祖GANやDCGANは生成画像が完全にランダムではありましたが、CGANではラベルをつけることで、指定した画像が生成できるようになります。上記GIFは0~9までの数値を順番で生成するようにしています。
 【PyTorch】元祖GANの仕組みは?画像生成PGも実装してみる【コードあり】
【PyTorch】元祖GANの仕組みは?画像生成PGも実装してみる【コードあり】
 【PyTorch】DCGANで画像生成PGを実装してみる【コードあり】
【PyTorch】DCGANで画像生成PGを実装してみる【コードあり】
今回はPyTorch-GANリポジトリのCGANのコードを参考にしました。
参考
PyTorch-GAN/cgan.py at master · eriklindernoren/PyTorch-GANGithub
さっそく、CGANの基本的なイメージと実装方法について、紹介していきます!
CGANの実装イメージ
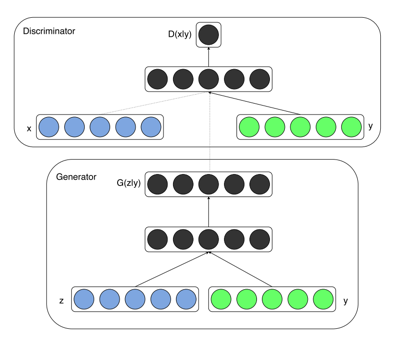
引用:【論文】Conditional Generative Adversarial Nets
CGANのアイデアは意外とシンプルで、生成器に入力するノイズ、また判別機に入力する画像に対し、ラベル情報も入れるだけです。
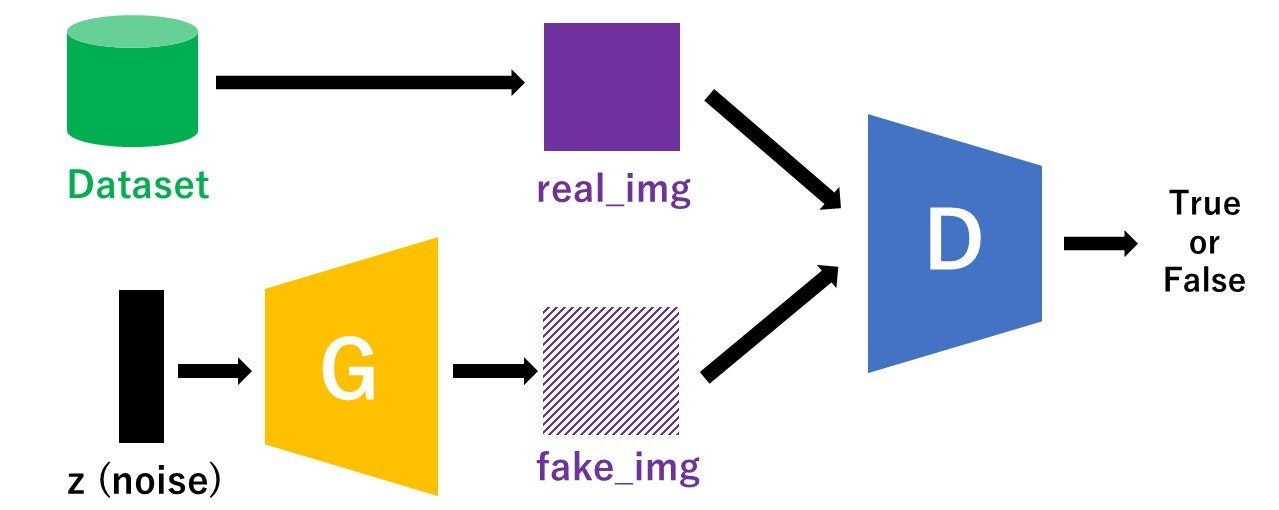
引用:cGAN(conditional GAN)でくずし字MNIST(KMNIST)の生成
それ以外の基本的な考え方は、元祖GANと同じになります。
参考 今さら聞けないGAN(6) Conditional GANの実装Qiita実装
それではGoogle Colaboratoryで実装していきます。最終ゴールをMNISTで0~9の数値を生成できるように学習させることです!
STEP1:下準備
まず下準備として、必要なパッケージをインストールし、MNISTのdataloaderを用意します。
import argparse
import os
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
また生成した画像の保存先フォルダも先に作っておきましょう。
os.makedirs("images", exist_ok=True)
続いて、CGANに関係するパラメータ(バッチサイズや画像サイズなど)を定義します。画像サイズもよく使うのでw
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--n_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args([])
#画像サイズ(チャンネル、縦サイズ、横サイズ)
img_shape = (opt.channels, opt.img_size, opt.img_size)
そして、MNISTのデータセットをダウンロードします。
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
dataloaderの中身を確認してみます。
batch_iterator = iter(dataloader) # イテレータに変換
imgs = next(batch_iterator) # 戦闘から要素を取得
print(imgs[0].shape) #imgs[0]:画像データ
>>> torch.Size([64, 1, 32, 32])
print(imgs[1].shape) #imgs[1]:ラベル
print(imgs[1])
>>> tensor([3, 0, 3, 5, 7, 4, 9, 3, 0, 8, 6, 8, 2, 0, 0, 1, 0, 4, 0, 9, 6, 2, 2, 9,
1, 1, 6, 4, 4, 0, 2, 8, 9, 3, 1, 0, 1, 0, 3, 1, 0, 2, 4, 9, 2, 5, 1, 1,
3, 1, 3, 4, 7, 1, 9, 0, 1, 6, 1, 1, 1, 6, 0, 7])
最後にGPUの定義をすれば、準備完了です!
cuda = True if torch.cuda.is_available() else False
STEP2:Generatorの定義
STEP2では、Generatorの定義をしていきます。Generatorにノイズ&ラベルを入力するイメージは以下のようになります。
FloatTensor = torch.FloatTensor
LongTensor = torch.LongTensor
# ノイズ生成:torch.Size([64, 1])
#64:バッチサイズ
z = FloatTensor(np.random.normal(0, 1, (opt.batch_size, opt.latent_dim)))
# 0 ~ 9のラベルをランダムで生成:torch.Size([64, 1])
gen_labels = LongTensor(np.random.randint(0, opt.n_classes, opt.batch_size))
print(gen_labels)
>>> tensor([1, 8, 9, 2, 2, 8, 5, 7, 2, 8, 3, 3, 2, 0, 8, 9, 2, 0, 9, 5, 7, 1, 6, 5,
5, 1, 2, 6, 9, 5, 7, 0, 2, 7, 2, 7, 4, 8, 3, 2, 1, 2, 9, 7, 8, 1, 3, 0,
2, 9, 7, 8, 6, 7, 0, 6, 2, 8, 2, 6, 2, 7, 0, 4])
#ベクトル => 行列に変更するための道具
label_emb = nn.Embedding(opt.n_classes, opt.n_classes)
# torch.Size([64, 1]) => torch.Size([64, 10])
gen_labels_emb = label_emb(gen_labels)
# ノイズとラベル情報を1つの行列に結合
# torch.Size([64, 100]), torch.Size([64, 10]) => torch.Size([64, 110])
gen_input = torch.cat((gen_labels_emb, z), -1)
ラベル情報は、ベクトルではなく行列として登録する必要があります。1番シンプルな例を挙げると、0,1,2から0のラベルを付けたいときは、0だけ渡すのではなく、[1, 0, 0]と渡してあげればOKです。
0 or 1ではなく、条件さえ決めてあげれば何でもOKです。今回はEmbedding関数を使って、ラベル情報をベクトルから行列にします。
上記を踏まえて、Generatorを定義すると、以下のようになります。
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# GPUで処理するときのために、init関数内にlabel_embを定義
self.label_emb = nn.Embedding(opt.n_classes, opt.n_classes)
self.layer1 = nn.Sequential(
nn.Linear(opt.latent_dim + opt.n_classes, 128),
nn.LeakyReLU(0.2, inplace=True)
)
self.layer2 = nn.Sequential(
nn.Linear(128, 256),
nn.BatchNorm1d(256, 0.8),
nn.LeakyReLU(0.2, inplace=True)
)
self.layer3 = nn.Sequential(
nn.Linear(256, 512),
nn.BatchNorm1d(512, 0.8),
nn.LeakyReLU(0.2, inplace=True)
)
self.layer4 = nn.Sequential(
nn.Linear(512, 1024),
nn.BatchNorm1d(1024, 0.8),
nn.LeakyReLU(0.2, inplace=True)
)
self.last = nn.Sequential(
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh(),
)
def forward(self, z, labels):
#ノイズ&ラベルを1セットにする処理
gen_input = torch.cat((self.label_emb(labels), z), -1)
out = self.layer1(gen_input)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.last(out)
#バッチサイズ分×img_shapeに展開
img = out.view(out.size(0), *img_shape)
return img
ちゃんとGeneratorが画像生成できるかどうか確認します。
# 動作確認
import matplotlib.pyplot as plt
z = torch.FloatTensor(np.random.normal(0, 1, (opt.batch_size, opt.latent_dim)))
labels = torch.LongTensor(np.random.randint(0, opt.n_classes, opt.batch_size))
G = Generator()
fake_imgs = G(z, labels) # torch.Size([64, 1, 64, 64])
# detach=>numpy型に変換
img_transformed = fake_imgs[0].detach().numpy() ## (1, 64, 64)
# チャンネル数、高さ、横 => 高さ、横
img_transformed = np.squeeze(img_transformed)
plt.imshow(img_transformed, 'gray')
plt.show()
こんなノイズ画像が生成さればOKです!
STEP3:Discriminatorの定義
続いて、判別機の定義をしていきます。基本的には元祖GANと同じです
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.label_embedding = nn.Embedding(opt.n_classes, opt.n_classes)
self.model = nn.Sequential(
nn.Linear(opt.n_classes + int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1),
nn.Sigmoid(),
)
def forward(self, img,labels):
# img.size(0):バッチ数
# img_flatのサイズ:(バッチ数, チャンネル数 × 高さ × 横)
img_flat = img.view(img.size(0), -1)
# d_inのサイズ:(バッチ数, チャンネル数 × 高さ × 横 + ラベルの種類数)
# 入力画像とラベル行列を結合
d_in = torch.cat((img_flat, self.label_embedding(labels)), -1)
validity = self.model(d_in)
return validity
判別機が正常に動作するか、確認しましょう。
FloatTensor = torch.FloatTensor
LongTensor = torch.LongTensor
z = FloatTensor(np.random.normal(0, 1, (opt.batch_size, opt.latent_dim)))
labels = LongTensor(np.random.randint(0, opt.n_classes, opt.batch_size))
G = Generator()
fake_imgs = G(z, labels)
D = Discriminator()
d_out = D(fake_imgs, labels)
print(d_out[0])
>>> tensor([0.4869], grad_fn=)
ちゃんと確率が返ってきたことを確認できました!
STEP4:学習
生成器、識別機を定義できたので、いよいよ学習です。まずは、学習前の準備を行います。
# Loss function:バイナリクロスエントロピー
adversarial_loss = torch.nn.BCELoss()
# generator and discriminator、インスタンス化
generator = Generator()
discriminator = Discriminator()
# GPU使用できる場合は、GPUに転送
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Optimizers:adam
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# GPU使う場合は、GPU内でtensor定義できるように準備
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
続いて、0~9の画像を生成する関数を定義します。
def sample_image(batches_done):
#100画像分の種となるノイズ
z = FloatTensor(np.random.normal(0, 1, (100, opt.latent_dim)))
#0,1…9が10回繰り返されたラベルベクトル
labels = np.array([num for _ in range(10) for num in range(10)])
labels = LongTensor(labels)
#画像生成
gen_imgs = generator(z, labels)
#画像保存
save_image(gen_imgs.data, "images/%d.png" % batches_done, nrow=10, normalize=True)
後は学習です!ラベル生成以外は、元祖GANと殆ど変わりません。
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
batch_size = imgs.shape[0]
# Adversarial ground truths
valid = FloatTensor(batch_size, 1).fill_(1.0)
fake = FloatTensor(batch_size, 1).fill_(0.0)
# GPUで使えるように設定
real_imgs = imgs.type(FloatTensor)
labels = labels.type(LongTensor)
# 勾配リセット
optimizer_G.zero_grad()
optimizer_D.zero_grad()
################
# 生成器 訓練
################
# ノイズ生成
z = FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim)))
# ラベル生成
gen_labels = LongTensor(np.random.randint(0, opt.n_classes, batch_size))
# 偽物生成
fake_imgs = generator(z,gen_labels)
# 損失関数の算出
g_loss = adversarial_loss(discriminator(fake_imgs, gen_labels), valid)
# 逆伝播
g_loss.backward()
# パラメータ更新
optimizer_G.step()
################
# 判別器 訓練
################
# 本物と偽物、2つを見分けられるように損失関数を計算
real_loss = adversarial_loss(discriminator(real_imgs, labels), valid)
fake_loss = adversarial_loss(discriminator(fake_imgs.detach(), gen_labels), fake)
# 損失値の平均
d_loss = (real_loss + fake_loss) / 2
#バックフォワード
d_loss.backward()
#パラメータ更新
optimizer_D.step()
print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader)
if batches_done % 5 == 0:
sample_image(batches_done=batches_done)
15分ほど経つと、学習が終わります。最後に生成された画像をGIF化しましょう。
from PIL import Image
import glob
files = sorted(glob.glob('images/*.png'))
images = list(map(lambda file : Image.open(file) , files))
images[0].save('images_gif.gif' , save_all = True , append_images = images[1:] , duration = 400 , loop = 0)
このように、0~9の画像が順番に敷き詰められたGIFが出力されたらバッチリです!



コメントを残す