
どーも、ぐるたか@guru_takaです。
ここ最近、ずっと気になっていたGANについて学び始めました。ここでは備忘録もかねて、初学者向けに、GANの仕組みをまとめました。またGIFのような簡単な画像生成のPGも、紹介します!

目次
GNAとは?
GANとはGenera tive Adversarial Networkの略称で、日本語で『敵対的生成ネットワーク』といいます。
GANとは、データから特徴を学習し、実在しないデータを生成したり、存在するデータの特徴に沿って変換できる生成モデルの1つです。
GANの研究は盛んになり、存在しないベッドルームや人間の顔を作り出したり、馬⇔シマウマに変換したり等、色々なGANたちが生まれています。

出典:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks

出典:A Style-Based Generator Architecture for Generative Adversarial Networks

出典:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
GANの仕組み
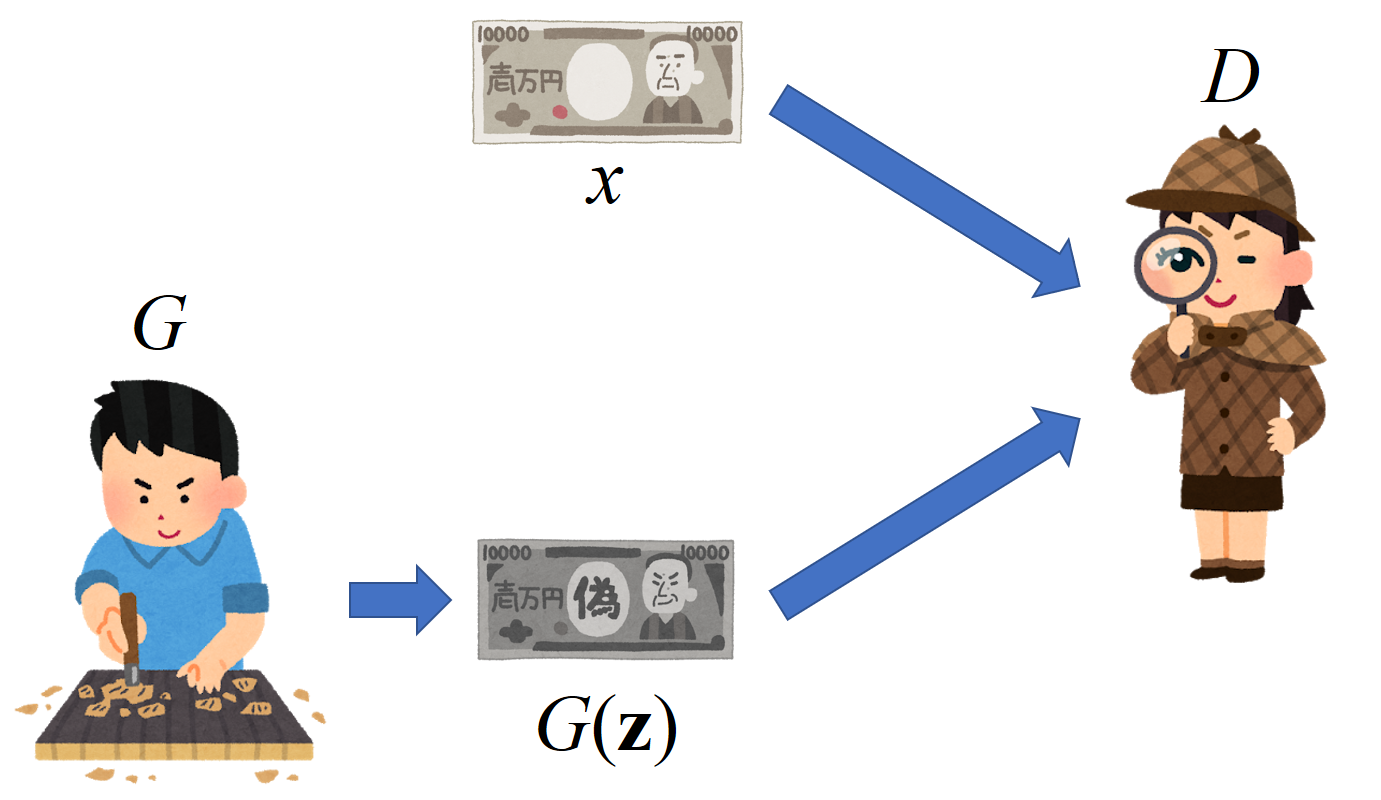
上記画像はGANの仕組みを「いらすとや」でわかりやすくまとめたものです。登場キャラクターはこんな感じ!
| 文字 | 名称 | 役割 |
| G | Generator(生成器) | 偽物を作り出す |
| D | Discriminator(識別器) | 本物、偽物を見極める |
| z | ノイズ | 生成器の種 |
| x | 本物のデータ | 生成したい特徴の源 |
学習イメージは以下の通りです。
- 生成器は精巧な偽札(生成データ)を作成
生成器はより本物に近い偽札を作り、識別器は見抜く力を高め、お互いが競い合います。イタチごっこを繰り返した結果、生成データは本物に限りなく近いものがでてくるのです!
目的関数
以下の式が、GANの目的関数になります。
$$
\min _{G} \max _{D} V(D, G)=\min _{G} \max _{D} \mathbb{E}_{x \sim p_{\text {data}}(x)}[\log D(x)]+\mathbb{E}_{z \sim p_{z}(z)}[\log (1-D(G(z)))]
$$
目的関数は識別器Dと生成器Gの2つの視点から考えていくと、意外とシンプルです。
まず、識別器Dから考えます。識別器Dは訓練データらしいかどうか、0~1で判断します。識別器Dの目的は2つ!
- xは本物なので、D(x)を1にしたい
- G(z)は偽物なので、D(G(z))を0にしたい
一方で、生成器Gの目的は以下になります。
- 識別器Dを騙して、D(G(z))を1に近づけたい
これらの目的を満たした目的関数が以下の式となります。
$$
\min _{G} \max _{D} V(D, G)=\min _{G} \max _{D} \mathbb{E}_{x \sim p_{\text {data}}(x)}[\log D(x)]+\mathbb{E}_{z \sim p_{z}(z)}[\log (1-D(G(z)))]
$$
よりわかりやすい目的関数の導出は以下の記事が凄く参考になりました。気になる方はチェックしてみて下さい!
参考 今さら聞けないGANの目的関数Qiita元祖GANの実装
ここからPyTorchで元祖GANで画像生成するPGを構築していきます!開発環境はGoogle Colaboratoryです。ランタイムのタイプを「GPU」にするのを忘れずに!
MNISTを使って、7, 8の画像を生成してみます!
参考にしたコードはPyTorchの公式リポジトリです。噛み砕いて、わかりやすく解説していきます。
参考
PyTorch-GAN/gan.py at master · eriklindernoren/PyTorch-GANGithub
7, 8の画像ダウンロード
「つくりながら学ぶ! PyTorchによる発展ディープラーニング」に紹介されているコードで、MNISTの画像をダウンロードします。
参考 pytorch_advanced/make_folders_and_data_downloads.ipynb at master · YutaroOgawa/pytorch_advanced
import os
import urllib.request
import zipfile
import tarfile
import matplotlib.pyplot as plt
%matplotlib inline
from PIL import Image
import numpy as np
# フォルダ「data」が存在しない場合は作成する
data_dir = "./data/"
if not os.path.exists(data_dir):
os.mkdir(data_dir)
import sklearn
# MNISTの手書き数字画像をダウンロードし読み込みます(2分ほど時間がかかります)
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1, data_home="./data/")
# data_homeは保存先を指定します
# データの取り出し
X = mnist.data
y = mnist.target
# フォルダ「data」の下にフォルダ「img_78」を作成する
data_dir_path = "./data/img_78/"
if not os.path.exists(data_dir_path):
os.mkdir(data_dir_path)
# MNISTから数字7、8の画像だけフォルダ「img_78」に画像として保存していく
count7=0
count8=0
max_num=200 # 画像は200枚ずつ作成する
for i in range(len(X)):
# 画像7の作成
if (y[i] is "7") and (count7<max_num):
file_path="./data/img_78/img_7_"+str(count7)+".jpg"
im_f=(X[i].reshape(28, 28)) # 画像を28×28の形に変形
pil_img_f = Image.fromarray(im_f.astype(np.uint8)) # 画像をPILに
pil_img_f = pil_img_f.resize((64, 64), Image.BICUBIC) # 64×64に拡大
pil_img_f.save(file_path) # 保存
count7+=1
# 画像8の作成
if (y[i] is "8") and (count8<max_num):
file_path="./data/img_78/img_8_"+str(count8)+".jpg"
im_f=(X[i].reshape(28, 28)) # 画像を28*28の形に変形
pil_img_f = Image.fromarray(im_f.astype(np.uint8)) # 画像をPILに
pil_img_f = pil_img_f.resize((64, 64), Image.BICUBIC) # 64×64に拡大
pil_img_f.save(file_path) # 保存
count8+=1
実行後、こんな風に画像が作られていればOK!
パッケージインポート&パラメータ定義
続いて、GANに必要なパッケージをインポート。その後、画像サイズなどのパラメータを設定します。
DataLoader作成の準備にもなっています!
# パッケージのimport
import random
import math
import time
import pandas as pd
import numpy as np
from PIL import Image
import torch
import torch.utils.data as data
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision.utils import save_image
from torchvision import transforms
# Setup seeds
torch.manual_seed(1234)
np.random.seed(1234)
random.seed(1234)
# パラメータ定義
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=64, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=3, help="interval betwen image samples")
opt = parser.parse_args([])
DataLoaderの作成
次にMNISTから数字7、8画像のDataLoader作成をしていきます。引き続き、「つくりながら学ぶ! PyTorchによる発展ディープラーニング」のGithubリポジトリのコードを参考にしています。
参考 pytorch_advanced/5-1-2_DCGAN.ipynb at master · YutaroOgawa/pytorch_advancedコードに一部私のコメントも追加しました。
import torch.utils.data as data
def make_datapath_list():
"""学習、検証の画像データとアノテーションデータへのファイルパスリストを作成する。 """
train_img_list = list() # 画像ファイルパスを格納
for img_idx in range(200):
img_path = "./data/img_78/img_7_" + str(img_idx)+'.jpg'
train_img_list.append(img_path)
img_path = "./data/img_78/img_8_" + str(img_idx)+'.jpg'
train_img_list.append(img_path)
return train_img_list
class ImageTransform():
"""画像の前処理クラス"""
def __init__(self, mean, std):
self.data_transform = transforms.Compose([
transforms.Resize(opt.img_size),#パラメータで定義した画像サイズ
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
def __call__(self, img):
return self.data_transform(img)
class GAN_Img_Dataset(data.Dataset):
"""画像のDatasetクラス。PyTorchのDatasetクラスを継承"""
def __init__(self, file_list, transform):
self.file_list = file_list
self.transform = transform
# shuffleで必要
def __len__(self):
'''画像の枚数を返す'''
return len(self.file_list)
def __getitem__(self, index):
'''前処理をした画像のTensor形式のデータを取得'''
# 画像取得
img_path = self.file_list[index]
img = Image.open(img_path) # [高さ][幅]白黒
# 画像の前処理
img_transformed = self.transform(img)
return img_transformed
# DataLoaderの作成と動作確認
# ファイルリストを作成
train_img_list=make_datapath_list()
# Datasetを作成
mean = (0.5,)
std = (0.5,)
train_dataset = GAN_Img_Dataset(
file_list=train_img_list,
transform=ImageTransform(mean, std))
# DataLoaderを作成
batch_size = 64
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True
)
# 動作の確認
batch_iterator = iter(train_dataloader) # イテレータに変換
imgs = next(batch_iterator) # 1番目の要素を取り出す
print(imgs.size()) # torch.Size([64, 1, 64, 64])
Generatorの定義
下準備は終わりです。いよいよGANの実装に入ります!
最初にGeneratorの定義していきます。
まずは、画像サイズ、GPU利用の可否、ノイズの次元を定義しちゃいましょう!
# 画像サイズ
img_shape = (opt.channels, opt.img_size, opt.img_size)
# GPU可否
cuda = True if torch.cuda.is_available() else False
# ノイズ次元
z_dim = opt.latent_dim
次に、Generatorのクラスを定義します。公式リポジトリにはLayerが綺麗にまとめているのですが、ここでは、わかりやすさ重視で分解しています。
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# ノイズ次元 100 => 128
# 活性化関数:LeakyReLU
self.layer1 = nn.Sequential(
nn.Linear(z_dim, 128),
nn.LeakyReLU(0.2, inplace=True)
)
# 128 => 256
# バッチノーマリゼーション:3次元なのでBatchNorm1d
# 活性化関数:LeakyReLU
self.layer2 = nn.Sequential(
nn.Linear(128, 256),
nn.BatchNorm1d(256, 0.8),
nn.LeakyReLU(0.2, inplace=True)
)
# 256 => 512
# バッチノーマリゼーション
# 活性化関数:LeakyReLU
self.layer3 = nn.Sequential(
nn.Linear(256, 512),
nn.BatchNorm1d(512, 0.8),
nn.LeakyReLU(0.2, inplace=True)
)
# 512 => 1024
# バッチノーマリゼーション
# 活性化関数:LeakyReLU
self.layer4 = nn.Sequential(
nn.Linear(512, 1024),
nn.BatchNorm1d(1024, 0.8),
nn.LeakyReLU(0.2, inplace=True)
)
# 1024 => チャンネル数 × 高さ × 横
# 活性化関数:Tanh
self.layer5 = nn.Sequential(
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
out = self.layer1(z)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
#(バッチサイズ,チャンネル数,高さ,横)に変換
img = img.view(img.size(0), *img_shape)
return img
ちゃんと、Generatorが動くかどうか、チェックします。
# 乱数生成
z = torch.randn(imgs.shape[0], opt.latent_dim)
#generatorインスタンス化
G = Generator()
# 偽物データ生成
fake_imgs = G(z)
# detach=>numpy型に変換
img_transformed = fake_imgs[0].detach().numpy()
# チャンネル数、高さ、横 => 高さ、横
img_transformed = np.squeeze(img_transformed)
plt.imshow(img_transformed, 'gray')
plt.show()
こんな風に白黒のノイズ画像が出てくればOKです!
Discriminatorの定義
次にDiscriminatorを定義します。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
# 入力:チャンネル数 × 高さ × 横
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
# img.size(0):バッチ数
# img_flatのサイズ:(バッチ数, チャンネル数 × 高さ × 横)
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
諸々のインスタンス化や定義
ここでは学習前に、生成器や識別器、損失関数などのインスタンス化をしていきます。
またGPUで動かすためにデータの転送もします。
# Loss function:バイナリクロスエントロピー
adversarial_loss = torch.nn.BCELoss()
# generator and discriminator、インスタンス化
generator = Generator()
discriminator = Discriminator()
# GPU使用できる場合は、GPUに転送
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Optimizers:adam
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# GPU使う場合は、GPU内でtensor定義できるように準備
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
動作の確認
ここからは、1イテレーション分の動作確認をしてみます。
まずはGeneratorから動かしてみます。
# 1バッチ単位のサイズ確認
imgs.size() #torch.Size([64, 1, 64, 64])
# 画像1つのデータサイズ
imgs[0].size() #torch.Size([1, 64, 64])
# GPUで動くTnesor型に変更
real_imgs = imgs.type(Tensor)
# imgs.shape[0] => ミニバッチ数
# ノイズ生成:0~1の値:ランダム
z = Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim)))
z.shape # torch.Size([64, 100])
# 生成データ
gen_imgs = generator(z)
# 目標値をミニバッチ分、用意
valid = Tensor(imgs.size(0), 1).fill_(1.0) #サイズ:torch.Size([64, 1]) 全て1
fake = Tensor(imgs.size(0), 1).fill_(0.0) #サイズ:torch.Size([64, 1]) 全て
# 損失関数の算出
# 生成器の視点なので、本物に近づけたい => 目標値はvalid
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
# 逆伝播
g_loss.backward()
#パラメータ更新
optimizer_G.step()
次に、判別器を動かしてみます。
# 本物と偽物、2つを見分けられるように損失関数を計算
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
# 損失値の平均
d_loss = (real_loss + fake_loss) / 2
#バックフォワード
d_loss.backward()
#パラメータ更新
optimizer_D.step()
問題なく動いていそうなので、このまま学習させてしまいます!
GAN学習
まずは諸々のインスタンス化をします。
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# フォルダ「gen_imgs」が存在しない場合は作成する
# ganで生成されたデータを保存
data_dir = "./gen_imgs/"
if not os.path.exists(data_dir):
os.mkdir(data_dir)
待ちに待った学習です!
for epoch in range(opt.n_epochs):
for i, imgs in enumerate(train_dataloader):
# 訓練ラベル
valid = Tensor(imgs.size(0), 1).fill_(1.0)
fake = Tensor(imgs.size(0), 1).fill_(0.0)
# GPUでも使えるように設定
real_imgs = imgs.type(Tensor)
#勾配リセット
optimizer_G.zero_grad()
optimizer_D.zero_grad()
################
# 生成器 訓練
################
# ノイズ生成
# imgs.shape[0] => バッチサイズ
z = Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim)))
# 偽物の画像生成
fake_imgs = generator(z)
# 損失関数の算出
g_loss = adversarial_loss(discriminator(fake_imgs), valid)
#バックフォワード
g_loss.backward()
#パラメータ更新
optimizer_G.step()
################
# 判別器 訓練
################
# 本物と偽物、2つを見分けられるように損失関数を計算
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(fake_imgs.detach()), fake)
# 損失値の平均
d_loss = (real_loss + fake_loss) / 2
#バックフォワード
d_loss.backward()
#パラメータ更新
optimizer_D.step()
print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(train_dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(train_dataloader)
if batches_done % opt.sample_interval == 0:
save_image(fake_imgs.data[:10], "gen_imgs/%d.png" % batches_done, nrow=5, normalize=True)
こんな画像がでたら終了です。お疲れ様でした!

生成された画像のGIF化
せっかくなので、最後に生成された画像をGIF化してみます。
from PIL import Image
import glob
files = sorted(glob.glob('gen_imgs/*.png'))
images = list(map(lambda file : Image.open(file) , files))
images[0].save('gen_imgs_gif.gif' , save_all = True , append_images = images[1:] , duration = 400 , loop = 0)
ノイズの状態から徐々に良い感じの7, 8画像が生まれていますね。
生成され、最後に保存された画像も良い感じです。GAN凄い!!



コメントを残す