
どーも、ぐるたか@guru_takaです。
PyTorchでDCGANをGoogle Colaboratoryで実装し、画像生成してみました。
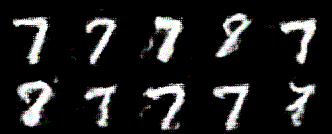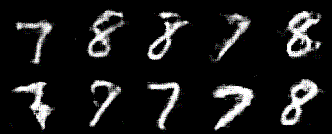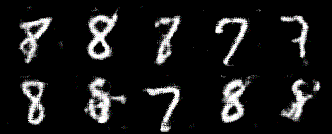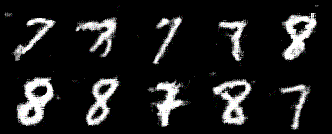

元祖GANと比べて、ノイズが少ない印象です!ここではDCGANの実装方法をまとめていきます。
GANの基本的な仕組みや実装方法はこちらの記事にまとめています。
 【PyTorch】元祖GANの仕組みは?画像生成PGも実装してみる【コードあり】
【PyTorch】元祖GANの仕組みは?画像生成PGも実装してみる【コードあり】
DCGANとは?
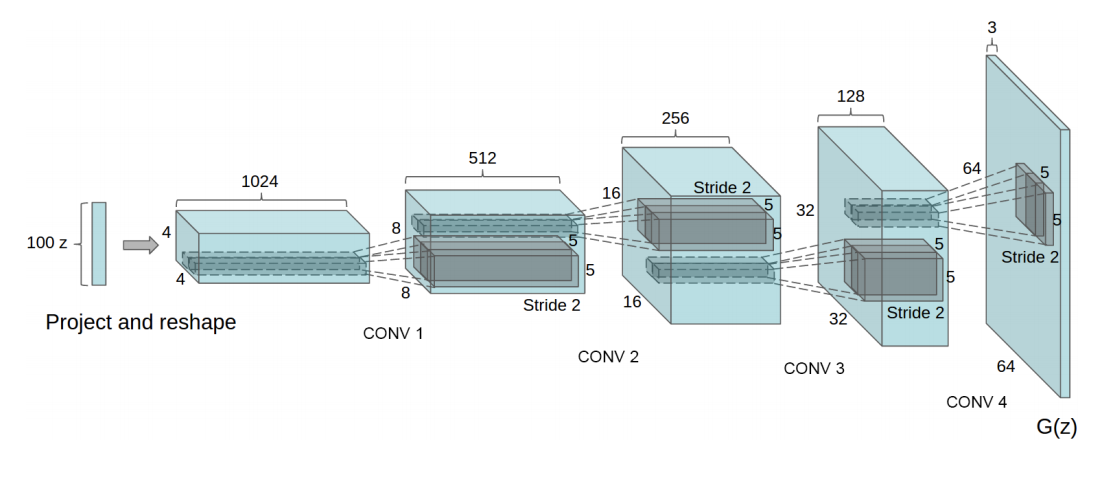
出典:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
DCGANとは、Deep Convolutional GANの略で、CNNを使用したモデルです。畳み込み層を入れることで表現力を上げ、高解像度な画像を生成できるようになりました。有名な存在しないベッドルームの画像も、DCGANで作られています。

出典:Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Generatorの入力は、画像に対して次元の小さいノイズになるため、逆畳み込み(ConvTranspose2d)を使います。ConvTranspose2dについては、以下のYoutube動画が非常にわかりやすかったので、気になる方はぜひチェックしてみて下さい。
DCGANの実装
GPUで動かすので、Google ColaboratoryのランタイムのタイプをGPUに設定しておきましょう。
準備
今回はDCGANでMNISTの7, 8の画像生成にトライします。MNISTの7, 8の画像ダウンロードは、元祖GANの実装の記事にまとめているので、コードのみ掲載いたします。
【PyTorch】元祖GANの仕組みは?画像生成PGも実装してみる【コードあり】
import os
import urllib.request
import zipfile
import tarfile
import matplotlib.pyplot as plt
%matplotlib inline
from PIL import Image
import numpy as np
# フォルダ「data」が存在しない場合は作成する
data_dir = "./data/"
if not os.path.exists(data_dir):
os.mkdir(data_dir)
import sklearn
# MNISTの手書き数字画像をダウンロードし読み込みます(2分ほど時間がかかります)
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1, data_home="./data/")
# data_homeは保存先を指定します
# データの取り出し
X = mnist.data
y = mnist.target
# フォルダ「data」の下にフォルダ「img_78」を作成する
data_dir_path = "./data/img_78/"
if not os.path.exists(data_dir_path):
os.mkdir(data_dir_path)
# MNISTから数字7、8の画像だけフォルダ「img_78」に画像として保存していく
count7=0
count8=0
max_num=200 # 画像は200枚ずつ作成する
for i in range(len(X)):
# 画像7の作成
if (y[i] is "7") and (count7<max_num):
file_path="./data/img_78/img_7_"+str(count7)+".jpg"
im_f=(X[i].reshape(28, 28)) # 画像を28×28の形に変形
pil_img_f = Image.fromarray(im_f.astype(np.uint8)) # 画像をPILに
pil_img_f = pil_img_f.resize((64, 64), Image.BICUBIC) # 64×64に拡大
pil_img_f.save(file_path) # 保存
count7+=1
# 画像8の作成
if (y[i] is "8") and (count8<max_num):
file_path="./data/img_78/img_8_"+str(count8)+".jpg"
im_f=(X[i].reshape(28, 28)) # 画像を28*28の形に変形
pil_img_f = Image.fromarray(im_f.astype(np.uint8)) # 画像をPILに
pil_img_f = pil_img_f.resize((64, 64), Image.BICUBIC) # 64×64に拡大
pil_img_f.save(file_path) # 保存
count8+=1
ダウンロードが完了した後、必要なパッケージをインストール、生成画像を保存先として images フォルダの作成、そしてパラメータの定義を行います。
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
# imagesフォルダ作成
os.makedirs("images", exist_ok=True)
# パラメータ定義
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=64, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=3, help="interval betwen image samples")
opt = parser.parse_args([])
続いて、DataLoaderを作成します。こちらも元祖GANの実装コードと同じなので、コードのみ掲載します。
【PyTorch】元祖GANの仕組みは?画像生成PGも実装してみる【コードあり】
import torch.utils.data as data
def make_datapath_list():
"""学習、検証の画像データとアノテーションデータへのファイルパスリストを作成する。 """
train_img_list = list() # 画像ファイルパスを格納
for img_idx in range(200):
img_path = "./data/img_78/img_7_" + str(img_idx)+'.jpg'
train_img_list.append(img_path)
img_path = "./data/img_78/img_8_" + str(img_idx)+'.jpg'
train_img_list.append(img_path)
return train_img_list
class ImageTransform():
"""画像の前処理クラス"""
def __init__(self, mean, std):
self.data_transform = transforms.Compose([
transforms.Resize(opt.img_size),#パラメータで定義した画像サイズ
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
def __call__(self, img):
return self.data_transform(img)
class GAN_Img_Dataset(data.Dataset):
"""画像のDatasetクラス。PyTorchのDatasetクラスを継承"""
def __init__(self, file_list, transform):
self.file_list = file_list
self.transform = transform
# shuffleで必要
def __len__(self):
'''画像の枚数を返す'''
return len(self.file_list)
def __getitem__(self, index):
'''前処理をした画像のTensor形式のデータを取得'''
# 画像取得
img_path = self.file_list[index]
img = Image.open(img_path) # [高さ][幅]白黒
# 画像の前処理
img_transformed = self.transform(img)
return img_transformed
# DataLoaderの作成と動作確認
# ファイルリストを作成
train_img_list=make_datapath_list()
# Datasetを作成
mean = (0.5,)
std = (0.5,)
train_dataset = GAN_Img_Dataset(
file_list=train_img_list,
transform=ImageTransform(mean, std),
)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size=opt.batch_size,
shuffle=True
)
次にGPUの定義をします。
cuda = True if torch.cuda.is_available() else False
そして、ネットワーク初期化の関数を定義します。
- 逆畳み込み層、畳み込み層の重み:平均0, 標準偏差0.02の正規分布
- バッチノーマリゼーションの重み:平均1, 標準偏差0,02の正規分布
- バイアス項:0
上記の初期値をすることで、DCGANでは経験的にうまくいくため、よく使用されます。
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
Generatorの定義
それでは、Generatorを定義します。「つくりながら学ぶ! PyTorchによる発展ディープラーニング」のGithubリポジトリのコードを参考にしました。

逆畳み込み後のサイズの変化をコメントしました。
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# torch.Size([64, 100, 1, 1]) =>torch.Size([64, 512, 4, 4])
self.layer1 = nn.Sequential(
nn.ConvTranspose2d(opt.latent_dim, opt.img_size * 8, kernel_size=4, stride=1),
nn.BatchNorm2d(opt.img_size * 8),
nn.ReLU(inplace=True)
)
# torch.Size([64, 512, 4, 4]) =>torch.Size([64, 256, 8, 8])
self.layer2 = nn.Sequential(
nn.ConvTranspose2d(opt.img_size * 8, opt.img_size * 4, kernel_size=4, stride=2,padding=1),
nn.BatchNorm2d(opt.img_size * 4),
nn.ReLU(inplace=True)
)
# torch.Size([64, 256, 8, 8]) =>torch.Size([64, 128, 16, 16])
self.layer3 = nn.Sequential(
nn.ConvTranspose2d(opt.img_size * 4, opt.img_size * 2, kernel_size=4, stride=2,padding=1),
nn.BatchNorm2d(opt.img_size * 2),
nn.ReLU(inplace=True)
)
# torch.Size([64, 128, 16, 16]) =>torch.Size([64, 64, 32, 32])
self.layer4 = nn.Sequential(
nn.ConvTranspose2d(opt.img_size * 2, opt.img_size, kernel_size=4, stride=2,padding=1),
nn.BatchNorm2d(opt.img_size),
nn.ReLU(inplace=True)
)
# torch.Size([64, 64, 32, 32]) =>torch.Size([64, 1, 64, 64])
self.last = nn.Sequential(
nn.ConvTranspose2d(opt.img_size, 1, kernel_size=4, stride=2,padding=1),
nn.Tanh(),
)
def forward(self, z):
# zの次元を拡張
z = z.view(z.shape[0], z.shape[1], 1, 1)
out = self.layer1(z)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.last(out)
return out
ConvTranspose2dのパラメータの意味については、こちらの記事が参考になります。
参考
PyTorchでのConvTranspose2dのパラメーター設定についてShikoan's ML Blog
念の為、Generatorの動作チェックをします。
# 動作確認
import matplotlib.pyplot as plt
z = torch.randn(imgs.shape[0], opt.latent_dim)
G = Generator()
# torch.Size([64, 1, 64, 64])
fake_imgs = G(z)
# detach=>numpy型に変換
# (1, 64, 64)
img_transformed = fake_imgs[0].detach().numpy()
# チャンネル数、高さ、横 => 高さ、横
img_transformed = np.squeeze(img_transformed)
plt.imshow(img_transformed, 'gray')
plt.show()
白黒のノイズ画像がでてくればOK!

Discriminatorの定義
次にDiscriminatorの定義をします。ここでポイントが4つあります。
- 活性化関数はLeakyReLU関数を使用
- プーリングをやめる
- 全結合層をなくし、global average poolingを使用
- Batch Normalizationを使わない
以下記事に簡単な解説がありますので、ぜひチェックしてみて下さい!
参考 はじめてのGANElix Tech Blog上記のポイントを踏まえ、Discriminatorを定義すると、以下のようになります。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# 白黒画像なので入力チャネルは1
# torch.Size([64, 1, 64, 64]) => # torch.Size([64, 64, 64, 64])
self.layer1 = nn.Sequential(
nn.Conv2d(1, opt.img_size, kernel_size=4,stride=2, padding=1),
nn.LeakyReLU(0.1, inplace=True)
)
# torch.Size([64, 64, 64, 64]) => # torch.Size([64, 128, 64, 64])
self.layer2 = nn.Sequential(
nn.Conv2d(opt.img_size, opt.img_size*2, kernel_size=4,stride=2, padding=1),
nn.LeakyReLU(0.1, inplace=True)
)
# torch.Size([64, 128, 64, 64]) => # torch.Size([64, 256, 64, 64])
self.layer3 = nn.Sequential(
nn.Conv2d(opt.img_size*2, opt.img_size*4, kernel_size=4,stride=2, padding=1),
nn.LeakyReLU(0.1, inplace=True)
)
# torch.Size([64, 256, 64, 64]) => # torch.Size([64, 512, 64, 64])
self.layer4 = nn.Sequential(
nn.Conv2d(opt.img_size*4, opt.img_size*8, kernel_size=4,stride=2, padding=1),
nn.LeakyReLU(0.1, inplace=True)
)
# torch.Size([64, 512, 64, 64]) => # torch.Size([64, 1, 64, 64])
self.last = nn.Conv2d(opt.img_size*8, 1, kernel_size=4, stride=1)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.last(out)
validity = nn.Sigmoid()(out)
return validity
Generatorと同じように、動作チェックします。
D = Discriminator()
z = torch.randn(imgs.shape[0], opt.latent_dim)
G = Generator()
# torch.Size([64, 1, 64, 64])
fake_imgs = G(z)
# 偽画像をDに入力 => 確率返す
d_out = D(fake_imgs)
# 出力d_outにSigmoidをかけて0から1に変換,1つ出力
print(d_out[0])
>>> tensor([[[0.4957]]], grad_fn=)
確率を出力すればOKです!
モデル学習
後は学習するのみです。まずは諸々のインスタンス化をしていきます。
# Loss function:バイナリクロスエントロピー
adversarial_loss = torch.nn.BCELoss()
# generator and discriminator、インスタンス化
generator = Generator()
discriminator = Discriminator()
# GPU使用できる場合は、GPUに転送
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Optimizers:adam
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# GPU使う場合は、GPU内でtensor定義できるように準備
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
そして、学習スタート!
for epoch in range(opt.n_epochs):
for i, imgs in enumerate(train_dataloader):
# 訓練ラベル
# valid => 正解なので1
# fake => 偽物なので0
valid = Tensor(imgs.shape[0], 1).fill_(1.0)
fake = Tensor(imgs.shape[0], 1).fill_(0.0)
# GPUで使えるように設定
real_imgs = imgs.type(Tensor)
# 勾配リセット
optimizer_G.zero_grad()
optimizer_D.zero_grad()
################
# 生成器 訓練
################
# ノイズ生成
# imgs.shape[0] => バッチサイズ
z = Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim)))
# 偽物生成
fake_imgs = generator(z)
# 損失関数の算出
g_loss = adversarial_loss(discriminator(fake_imgs), valid)
# 逆伝播
g_loss.backward()
# パラメータ更新
optimizer_G.step()
################
# 判別器 訓練
################
# 本物と偽物、2つを見分けられるように損失関数を計算
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(fake_imgs.detach()), fake)
# 損失値の平均
d_loss = (real_loss + fake_loss) / 2
#バックフォワード
d_loss.backward()
#パラメータ更新
optimizer_D.step()
print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(train_dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(train_dataloader)
if batches_done % opt.sample_interval == 0:
save_image(fake_imgs.data[:10], "images/%d.png" % batches_done, nrow=5, normalize=True)
学習が終わった後に、生成した画像をGIF化してみましょう!
from PIL import Image
import glob
files = sorted(glob.glob('images/*.png'))
images = list(map(lambda file : Image.open(file) , files))
images[0].save('images_gif.gif' , save_all = True , append_images = images[1:] , duration = 400 , loop = 0)

大変勉強させて頂いております。
コードをそのままGoogle Colaboratoryで実装してみたところ,
“DataLoaderを作成”のところで, エラー”NameError: name ‘opt’ is not defined”が出ます。
“#パラメータで定義した画像サイズ”の行だとは思いますが, 対処法をご教示頂けませんか?
何卒宜しくお願い申し上げます。
コメント、またご指摘
ありがとうございます。
パラメータの定義が欠けていました。大変失礼いたしました。
DataLoader 作成前に、以下のコードを読み込ませると、動作すると思います。
[codebox title="main.ipynb"]
[/codebox]
お手すきの際に、お試し頂けましたら幸いですm(_ _)m