
どーも、ぐるたか@guru_takaです。
Perfumeの分類器を作りたくて、試行錯誤でCNNを自作していましたが、思うような精度が出ませんでした。
そこで、ファインチューニングを試したら、めっちゃ良い精度が出たので、やり方をまとめました。初学者の参考になれば幸いです!
実装は弊社の以下の記事を超参考にしています!
参考 ファインチューニングKIKAGAKU特徴抽出器(畳み込みしている部分)をレンタルし、新しい分類器に適応させるイメージ!
参考
CNN 転移学習とファインチューニングQiita
目次
開発環境
- Google Colaboratory
- PyTorch:’1.4.0′
- PyTorch Lightning:’0.7.3′
実装したいもの
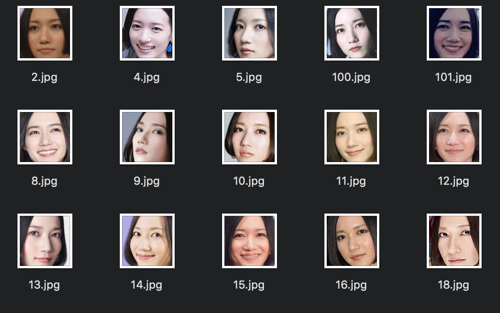
今回は、perfumeのメンバーを識別する分類器を作ります!
画像データはGoogleでスクレイピング、またインスタで良さげな写真を使いました。
 【Python】Google内で画像スクレイピング→OpenCVで顔だけ切り取る方法
【Python】Google内で画像スクレイピング→OpenCVで顔だけ切り取る方法
画像枚数は以下の通りです!
- のっち:124枚
- かしゆか:123枚
- あーちゃん:132枚
処理の流れ
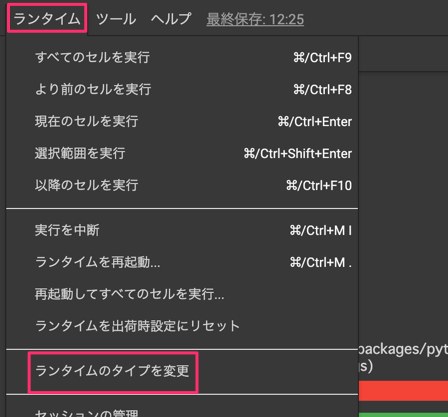
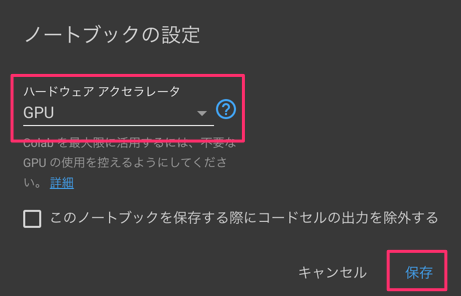
STEP.1:GPUをつけるように設定
Google ColaboratoryでGPUを使えるようにします。
STEP.2:画像アップロード
Perfumeの画像をアップロードします!
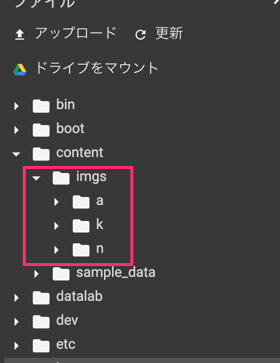
ここは各々のデータをアップロードして下さい。以下のコードは、imgsフォルダ内のデータを使っていきます。
STEP.3:前処理
まず最初に、モデル学習で使える画像データに変換(前処理)していきます!
さっそく、必要なモジュールをインストール!
# pytorch_lightningのインストール
!pip install pytorch_lightning
# pytorch関係
mport torch, torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms
import pytorch_lightning as pl
from pytorch_lightning import Trainer
# フォルダ内のデータ読込で使用
from PIL import Image
import glob
そして、画像パスを配列に格納します。
# 画像読み取り
fold_path = './imgs/'
imgs = []
for imgs_path in glob.glob(fold_path + '*'):
imgs.append(glob.glob(imgs_path + '/*'))
すると、[['a_1.jpg', 'a_2.jpg', …],['n_1.jpg', 'n_2.jpg', …],['k_1.jpg', 'k_2.jpg', …]]と画像パスがリストに入ります!
今回、ファインチューニングで使用する学習モデルは有名なResNet18です。便利なことに、簡単に学習済みモデルをインポートできます!
# 学習済みモデル「ResNet18」をインポート
from torchvision.models import resnet18
# 学習済みモデル「ResNet18」をダウンロード
resnet = resnet18(pretrained=True)
学習済みモデル「ResNet18」を使うには、入力データを学習済みモデルの仕様に合わせないといけません。詳細が気になる方はチェック!
参考
torchvision.models PyTorch master documentation
PyTorchには、データの前処理に使うメソッドtransforms.Composeが用意されています。リサイズも正規化など色々とメソッドが用意されていて、すっごい便利!
さっそく、前処理の関数を定義しましょう。
transform = transforms.Compose([
# 224×224にリサイズ
transforms.Resize((224, 224)),
# torch.Tensor型に変換
transforms.ToTensor(),
# 学習済みモデルで使われる平均と標準偏差で標準化
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
後は、ラベルと画像データをtorch.Tensor型でまとめます。
labels = []
img_datas = torch.tensor([])
# 画像データを配列に格納
# torch型に変更
for i,imgs_arr in enumerate(imgs):
for img_path in imgs_arr:
# ラベルを追加
labels.append(i)
# imgデータ(PIL型)の取得
img = Image.open(img_path)
# imgデータの前処理
tensor_img = transform(img)
# バッチサイズを追加: バッチサイズ, チャンネル, 高さ、幅
tensor_img = tensor_img.unsqueeze(0)
# torch.tensorのappend
img_datas = torch.cat([img_datas, tensor_img],dim=0)
最後に、訓練データと検証データに分けて、Dataset(入力データと目標データのセット)にまとめていきます!
# データセット化
datasets = torch.utils.data.TensorDataset(img_datas, labels)
# 訓練:検証 = 85% : 15%
n_train = int(len(datasets) * 0.85)
n_val = len(datasets) - n_train
# 擬似乱数のシード固定
torch.manual_seed(0)
# データセットを訓練用、検証用で分割
train,val = torch.utils.data.random_split(datasets,[n_train,n_val])
STEP.4:モデル学習
本題であるファインチューニングを使って、モデル学習していきます!
# 訓練用のクラス
class TrainNet(pl.LightningModule):
@pl.data_loader
def train_dataloader(self):
# ミニバッチ
return torch.utils.data.DataLoader(train, self.batch_size,shuffle=True)
def training_step(self, batch, batch_nb):
# 入力と目標値を分割
x, t = batch
y = self.forward(x)
loss = self.lossfun(y, t)
results = {'loss': loss}
return results
# 検証用のクラス
class ValidationNet(pl.LightningModule):
@pl.data_loader
def val_dataloader(self):
return torch.utils.data.DataLoader(val, self.batch_size)
def validation_step(self, batch, batch_nb):
x, t = batch
y = self.forward(x)
loss = self.lossfun(y, t)
y_label = torch.argmax(y, dim=1)
acc = torch.sum(t == y_label) * 1.0 / len(t)
results = {'val_loss': loss, 'val_acc': acc}
return results
def validation_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
avg_acc = torch.stack([x['val_acc'] for x in outputs]).mean()
results = {'val_loss': avg_loss, 'val_acc': avg_acc}
return results
# 学習用の全体のクラス
# 訓練用、検証用を継承
class FineTuningNet(TrainNet, ValidationNet):
# データ数が少ないのでbatch_sizeは大きめ
def __init__(self, batch_size=256):
super().__init__()
self.batch_size = batch_size
# 畳み込みの部分は学習済みモデルを活用
self.conv = resnet18(pretrained=True)
# 全結合層は1000 => 100 => 3
# 1000はresnet18の仕様
# 3は分類数(かしゆか、のっち、あーちゃん)
self.fc1 = nn.Linear(1000, 100)
self.fc2 = nn.Linear(100, 3)
# 学習済みのパラメータを固定
for param in self.conv.parameters():
param.requires_grad = False
def lossfun(self, y, t):
return F.cross_entropy(y, t)
def configure_optimizers(self):
return torch.optim.SGD(self.parameters(), lr=0.01)
def forward(self, x):
x = self.conv(x)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
return x
GPUを使って学習していきます!5分くらいかかります。
# 再現性の確保
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# 学習
fine_net = FineTuningNet()
trainer = Trainer(gpus=1, max_epochs=300)
trainer.fit(fine_net)
学習が終わったら、学習済みモデルの精度を確認しましょう。
trainer.callback_metrics
>>{'epoch': 299,
'loss': 0.017820697277784348,
'val_acc': 0.9122806787490845,
'val_loss': 0.21298980712890625}
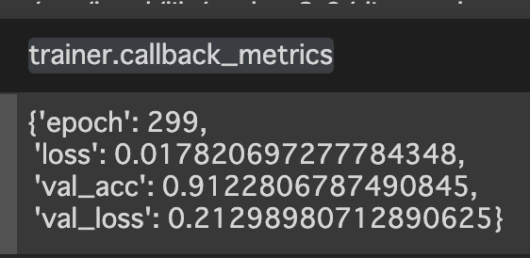
精度が91.2%と、めちゃくちゃ良さげ!自作CNNではこんなに良い精度はでませんでした。ファインチューニングの強さを感じます(強)
STEP.5:推論
さっそく、学習したモデルで推論してみましょう!
# unsqueeze:バッチサイズ1を追加
# cuda:GPUなので必要
x = val[0][0].unsqueeze(0).cuda()
# モデルモードを学習→推論に変更
fine_net.eval()
fine_net.freeze()
F.softmax(fine_net(x)), val[0][1]
すると、98%あってる結果が返ってきました。大成功です!
>> (tensor([[9.9845e-01, 7.9624e-05, 1.4681e-03]], device='cuda:0'), tensor(0))
STEP.6:モデル保存
最後に学習済みモデルを保存します。
# 学習済みモデルの保存
torch.save(fine_net.state_dict(), 'fine.pt')
保存した学習済みモデルのロード方法は以下の通りです!
# モデルの定義
fien_net_pred = FineTuningNet()
# 推論モード
fien_net_pred.eval()
fien_net_pred.freeze()
# 重みの読み込み
fien_net_pred.load_state_dict(torch.load('fine.pt'))
ちゃんと動くかどうか、確認してみます!
# サイズ確認
x = train[0][0].unsqueeze(0)
y_predict = fien_net_pred(x)
F.softmax(y_predict), train[0][1]
>> (tensor([[3.2377e-05, 9.5373e-01, 4.6236e-02]]), tensor(1))
問題なさそうですね!後はサーバーにデプロイしてあげれば、実運用できそうです。引き続き、Perfume分類器の開発、がんばります!!


コメントを残す