
どーも、ぐるたか@guru_takaです。
Perfume「あーちゃん・かしゆか・ノッチ」の分類器を作ろうと思い、データ集め→顔だけ画像を切り取ってみました!
ここでは、PythonでGoogleから画像スクレイピングする方法と、顔だけ切り取って再保存する方法を紹介します。前処理の参考になれば幸いです!
Googleから画像スクレイピングする方法
結論、こちらのリポジトリ(Licence:MIT)をクローンし、スクレイピングすると楽ちんです!
参考 Joeclinton1/google-images-download at patch-1Github本家だと以下の記事と同じようなエラーが出たので、Forkされ改善されたソースを活用しています。(2020/4/18時点)
参考 google image downloadが動かなかったのでその対応 - Qiitaスクレイピングのコマンドは簡単!
$ git clone https://github.com/Joeclinton1/google-images-download.git
$python3 google-images-download/google_images_download/google_images_download.py -k 取得したいキーワード
これだけでGoogleから画像スクレイピング→画像の保存までやってくれます!保存先はdownloadsフォルダです。
コマンドなどの詳細は公式ドキュメントや他の記事を参考にしてみて下さい!
参考 たった2つのコマンドで1000枚の画像をダウンロードするQiita 参考 Google Images Download documentationGoogle Images Downloadモデル学習後に精度を確認しますが、本人の画像がバッチリ映っているインスタからスクレイピングするのも選択肢の1つだと思いました!
参考 Instagramから大量の画像を集めるQiita画像から顔部分だけ切り取り→保存する方法
続いて、顔識別の精度を上げるために、保存した画像から顔だけ切り取って再保存する作業をします。
こんな感じで、公式のフィルターを使って顔を識別し、保存していきます!
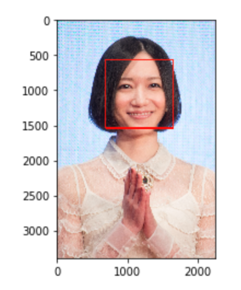
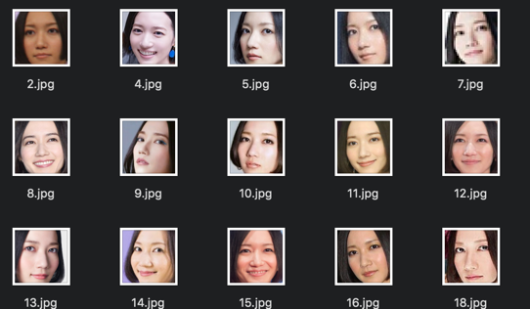
顔識別の方法ですが、opencvが公式で提供しているhaarcascade_frontalface_alt.xmlを使います。
参考
opencv/haarcascade_frontalface_alt.xml at master · opencv/opencv
ダウンロードして、各作業ディレクトリに保存しましょう!
ディレクトリ構造
こんなディレクトリ構造で話を進めていきます。
├── cutted_imgs
├── google-images-download
├── imgs
│ ├── cut_face # 顔だけ切り取った画像
│ │ ├── perfume_a
│ │ ├── perfume_k
│ │ └── perfume_n
│ └── original # スクレイピングで保存した画像
│ ├── perfume_a
│ ├── perfume_k
│ └── perfume_n
└── opencv
└── haarcascade_frontalface_alt.xml
コード
コードは以下の通りです。コメントで解説しています!
import cv2
import glob #ファイル読み込みで使用
import os #フォルダ作成で使用
# 顔識別のカスケード、インスタンス化
face_cascade = cv2.CascadeClassifier(cascade_path)
# スクレイピングした画像を全て読み取り
# perfumeのメンバー分、loop
for fold_path in glob.glob('./imgs/original/*'):
imgs = glob.glob(fold_path + '/*')
# 顔切り取り後の、画像保存先のフォルダ名
save_path = fold_path.replace('original','cut_face')
# 保存先のフォルダがなかったら、フォルダ作成
if not os.path.exists(save_path):
os.mkdir(save_path)
# 顔だけ切り取り→保存
# 画像ごとに処理
for i, img_path in enumerate(imgs,1):
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 顔がある座標4つを取得
# 顔が検知できないと、空の配列が返ってくる
# 1.1 => scaleFactor – 各画像スケールにおける縮小量
# 3 => minNeighbors – 近傍矩形を含む数
faces = face_cascade.detectMultiScale(img_gray, 1.1, 3)
if len(faces) > 0:
for j, face in enumerate(faces,1):
x, y ,w, h =face
save_img_path = cut_face_path + '/' + str(i) +'_' + str(j) + '.jpg'
cv2.imwrite(save_img_path , img[y:y+h, x:x+w])
else:
print ('image' + str(i) + ':NoFace')
以上です!
これだけで、顔だけの画像を保存できます。参考になれば幸いです!


コメントを残す